What's New in Axcelerate 5.15?
- Release Notes
- Click HERE to review the 5.15 Release Notes.
- New Feature Video
- Click Review in Context to view a video of this exciting new feature!
- Pause batches
- It is now possible to pause batches that are In review, so further action can be taken on the batch, such as change the assignee, rename the batch or close it.
- See: Pause a Batch
Wildcard searches starting with and, or, not find words that start with and, or, not, and also the actual terms and, or, not. The actual terms were not found in earlier product versions.
Also, the phrase search "and", "or", "not" now finds the actual term.
Note: This improvement may result in more search hits for some of your saved searches.
- Review in Context
- Review in Context is an alternative review method that provides new review efficiencies by focusing the review on document relationships, that is, families, email threads, duplicates and near duplicates. It maintains the context of these document relationships, alleviates distraction by displaying only metadata that is important based on a document's MIME type and, when appropriate, it helps reviewers tag related document sets consistently. This feature will be available in both new Axcelerate 5.15 projects and in existing projects that are upgraded to Axcelerate 5.15.
- See: Review in Context and Review Page vs. Review in Context
- Quick tags work a little differently when you group tag an associated document group using Review in Context.
- See: Quick Tags and Review in Context
- The default Review in Context settings can be configured within Axcelerate 5.
- See: Configure Review in Context
- The Review in Context settings, if configured in an Axcelerate template application, can also be cloned to a new Axcelerate Review & Analysis application.
- Also find details in the Administrator Help:
- See: Template Usage for Axcelerate 5 Front End Settings
- Review batches: split associated document groups
- If you select Full batching, split by document count in the batching configuration, associated document groups may be split across review batches. The system now checks the number of documents in a batch before adding the next group of associated documents. If the number of documents is up to 50 percent above or below the specified document count per batch, a new batch is created and a _SPLIT suffix is added to the batch name.
- See: Include Associated Documents
- Review consistency validation
- You can use field-based search to locate associated document sets that are not tagged consistently. This feature can be used on single value, multivalue, hierarchy, date, and numeric fields. It can also be used on the Review State field.
- See: Search for Inconsistent Tags
The viewing technology of the Axcelerate 5 front end has been partially replaced, to allow faster display of Near Native view. The new technology has less storage and memory requirements, and it requires less infrastructure and architecture overhead.
Furthermore, Near Native view and the Text/OCR display of Production view now offer the same search syntax as the keyword search for the Results list. Highlighting is more consistent in Text view, Near Native and Production view. There are very few limitations for highlighting in these views.
The new technology is not used for Redaction view, due to the specific storage requirements for redactions.
- Near Native view page navigation
- Near Native view for documents that contain more than 500 pages uses Page navigation mode even if you select Scroll as your preferred document viewing method on the User Preferences page.
- See: User Preferences Page
- PDF bookmarks navigator not available in Near Native view
- The PDF bookmarks navigator, which allows you to navigate between events in a chat message, is no longer available in Near Native view. It remains available in Redaction view, with the same functionality.
- Text-based annotation tools not supported
- The new viewer does not support the text-based annotation tools listed below and they are no longer available. However, annotations based on these tools will not be lost with an upgrade to Axcelerate 5.15.
 Changemark Text Strikethrough
Changemark Text Strikethrough- Allows you to strikethrough text and add a Changemark note at the same time.
 Changemark Text Highlight
Changemark Text Highlight- Allows you to highlight text and add a Changemark note at the same time.
 Strikeout
Strikeout- Allows you to strikeout text.
 Strikethrough
Strikethrough- Allows you to strikethrough text.
 Text Highlight
Text Highlight- Allows you to highlight text.
 Underline
Underline- Allows you to underline text.
The use of two document view technologies required some changes to the conversion process, the conversion wizard and the tracking of conversion results with Smart Filters.
- Conversion reasons for bulk conversion and preconversion rules have changed
- The new conversion reasons are:
- Near Natives
- Prepares documents for:
- Viewing in Near Native view
- Bulk printing of Near Native view
- Redactions & Production > Limited
- Prepares documents for:
- Production
- Global redaction
- Bulk printing of Image view (when a document has an image)
- Bulk printing of Redaction view
- Redactions & Production > All
- The same result as Redactions & Productions > Limited, but also prepares documents for:
- Viewing in Image view (when a document has an image)
- Viewing in Redaction view
- Actions menu option renamed
- The Review Display Storage option in the Analysis page Actions menu was renamed Clean up Redaction View Storage, as it no longer refers to Near Native view. There is no change in functionality.
- See: Redaction View Storage Cleanup
- See: Bulk Conversion and Preconversion Rules
- Files resulting from conversion
- Non-image documents are now converted to PDF for display in Near Native view.
- Image view and Redaction view continue to use the SVG viewer.
- For more technical details, see: On-The-Fly Conversion and Files Created and Stored by Bulk Conversion
- Smart Filters for conversion results
- Conversion results for Near Native view are tracked with the new Native View Preparation Smart Filter.
- See: Native View Preparation Smart Filter
- Conversion results for production and redaction are tracked with the Conversion Smart Filter.
- See: Conversion Smart Filter
- Conversion Smart Filter - Display Exception value
- A new Display Exception value is assigned to documents when conversion fails and a slip-sheet cannot be generated, which may occur when:
- There are errors converting for Image view.
- There are errors converting a document from Converted - Prepared for Production to Converted - Prepared for Redaction view.
- There are errors displaying a document which is already Converted - Prepared for Production.
- The conversion server is not responding.
- See: Conversion Smart Filter
Note: If a matter is upgraded to Axcelerate 5.15 and it contained a preconversion rule to convert documents for viewing, post upgrade you will see the existing rule was broken into two rules to account for the new conversion settings.
- Automatic preconversion for Marked for Redaction documents
- Documents that are marked for redaction are automatically submitted for preconversion for viewing in Redaction view every five minutes by default.
This operation is run by a system-internal preconversion rule that identifies documents with the Mark for Redaction flag. The job name is
Documents marked for redaction. Although these jobs are executed every five minutes, they are set to the lowest priority to ensure that jobs triggered by on-the-fly conversion and user-created preconversion rules are not blocked. This feature will be available in both new Axcelerate 5.15 projects and in existing projects that are upgraded to Axcelerate 5.15. - Native Conversion supports Microsoft Office 2013 and 2016
- Microsoft Office 2016 will be rolled out on Axcelerate Cloud systems after the Axcelerate 5.15 rollout. This may take some weeks.
The type-ahead text box of the Concept Groups Smart Filter allows users to search for display names of concept groups; however, the display name contained only the first three characteristic words for each concept group. The display names of concept groups now contain all of the listed characteristic words, so a user can search for any of them.
- Field display
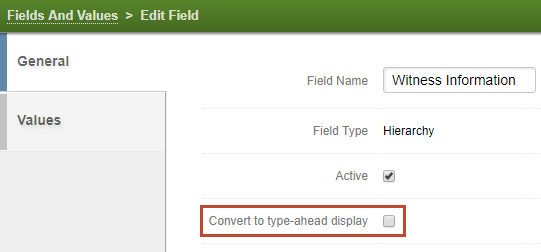
- Single value, multivalue and hierarchy fields that contain 300 or more values no longer auto-convert to a type-ahead text box display. Instead, the Axcelerate 5 Fields and Values page contains a Convert to type-ahead display check box that you can select to enable the feature.
- To modify the values of a field that has been converted to a type-ahead display using the Axcelerate 5 Fields and Values page, clear the Convert to type-ahead display check box, modify the values on the Values tab and then return to the General tab to select the Convert to type-ahead display check box again when your work is complete.
- See: Set Up a New Field and Modify Existing Fields
- Also find details in the Administrator Help:
- See: Type-Ahead Field Threshold Settings
- Field value preview on Values tab is now limited
- To prevent browser unresponsiveness, the Values tab for a field on the Axcelerate 5 Fields and Values page now displays only the first 1,000 field values for preview and editing. You will see a Load all values option; however, loading all values for a field that contains a very high number of values is likely to cause your browser to become unresponsive. If this occurs, you can still add or rename the field's values from the Tagging panel and an Administrator can delete values in CORE Administration.
Note: Active fields previously designated as type-ahead fields by the old threshold value will remain type-ahead fields after a project is upgraded to Axcelerate 5.15. If desired, you can then take advantage of this new setting to revert a field back to list style.
Axcelerate 5.15 supports Qlik Sense 2.0.7, also used in previous versions, and the new Qlik Sense February 2018.
Qlik Sense February 2018 contains a number of bug fixes relevant for Axcelerate 5.15.
Qlik Sense 2.0.7 is not supported by Qlik anymore. Therefore, the next Axcelerate version will not support it either.
A command-line feature called search-based enrichment allows you to extract information from documents and add it to metadata, after data has been loaded or published.
This allows, amongst others:
- Search for numeric or alphanumeric content with wildcards and tag containing documents.
- Search for PII patterns such as email addresses, phone numbers, personnel numbers and tag containing documents. Users then can find those documents that may need redaction, by filtering.
- Run the MIME type detector over CSV Load documents if the MIME type information is missing and add the information to the MIME type field.
- Values imported with publish or CSV merge can be shown in the Document History
- Up to now the Document History only displayed field values that were changed by user tagging. Starting with this version, values that come into Axcelerate Review & Analysis with a publish or a CSV merge can be displayed, if fields are configured appropriately.
- Production export snapshots removed
- Production export can now be run immediately from the Production Workflows page. The snapshots storage handler and the export database used for snapshots have been removed.
- See: Configure and Run a Production Export
- Production export jobs
- Production export is now run as a job. An error log file in CORE Administration allows improved tracking.
- Microsoft Outlook 2016 support
- For data loading, Microsoft Outlook 2013 and 2016 are supported. Microsoft Outlook 2010 is no longer supported.
- Lotus Notes 9 support
- For loading Lotus Notes files, the Lotus Notes 8.5.x or 9.x client can be used.
- Lotus Notes 9.x will be rolled out on Axcelerate Cloud systems after the Axcelerate 5.15 rollout. This may take some weeks.
- Lotus Notes folder extraction
- View/folder names in NSF archives can now be extracted.
- You can enable extraction in the data source configuration, with Parsers > Notes parsers > NSF Views/Folders > Extract view/folder names. Extraction uses regular expressions. In addition to the default extraction and substitution patterns, you can specify custom patterns. If you are processing Notes files and want to have the folder names extracted, you must ensure that the local buffering for Notes files is enabled. For setting up your specific data sources, ask Customer Support.
- Configurable domain default for X400 mail addresses
- When emails are sent within an exchange network, they never leave the network. If these internal emails are collected, they may be missing country code information. By default, the system automatically adds .com. This default top level domain is now configurable for X400 email address to SMTP conversion. The default remains .com, to keep current behavior and default to the most likely best name.
- Publish data source runs in 64-bit mode now and has configurable heap
- The 64-bit mode, in combination with a reasonable heap size, reduces the risk of out of memory exceptions during publishing.
- But the possible heap size depends on number of data sources and RAM. Therefore, after the update to Axcelerate 5.15, check this internal setting in the application configuration of Axcelerate Ingestion.
- Find details in the Administrator Help:
- See: Heap Size for Publish Data Sources
- Metadata Index for fast and low-memory ingestion
- With Metadata Index, you can ingest documents with as small memory, storage and hard disk usage as possible, within a minimum of time. Full processing, including text extraction, is done during the publish.
- Find details in the Administrator Help:
- See: Metadata Index
- Post processors can be disabled in bulk
- Especially conceived for data load tests, loading data without post processors helps you to understand the content and metadata of your data source and find out which fields you need to create.
- Disable postprocessing in the data source configuration, on the Postprocessing node.
- Find details in the Administrator Help:
- See: Data Load Test without Post Processing
- Less duplicates for protected documents
- Archives and parent files of attachment families are now checked for their modification date at a very early point of the data load. Especially for Axcelerate ECA & Collection, that protects published documents, this results in less duplicates that are loaded, and less storage volume.
- Smart Filter window can be resized
- Smart Filters on the Explore tab of CORE Administration and Axcelerate Ingestion can now be resized. Move your pointer over the right side or bottom of a Smart Filter window. When your pointer turns into a double arrow, left-click and drag the window to expand it. You can also click
 to fully maximize the window.
to fully maximize the window. - Search in
- Any value and No value options are now available in the Search in Smart Filter in CORE Administration and Axcelerate Ingestion. Select a field and then select the Any value or No value option and the filter is immediately applied.
Any value and No value options

- Family inclusion
- Family inclusion can now be applied as a sticky filter in Axcelerate Ingestion or CORE Administration by holding SHIFT and then clicking Include Family
 . This allows you to run a search on top of the family inclusion.
. This allows you to run a search on top of the family inclusion. - A lock
 displays in the Search Parameters panel to indicate the family inclusion is sticky. Click the lock to remove the sticky family inclusion.
displays in the Search Parameters panel to indicate the family inclusion is sticky. Click the lock to remove the sticky family inclusion. - If you click
 , the sticky family inclusion is removed, but it reappears if you run a new key word search. If you apply a Smart Filter instead of a key word search, you need to add the family inclusion again; however, once added it is automatically sticky.
, the sticky family inclusion is removed, but it reappears if you run a new key word search. If you apply a Smart Filter instead of a key word search, you need to add the family inclusion again; however, once added it is automatically sticky. - Family sort
- Family sort is enabled for Axcelerate Ingestion applications that use meta engines, in both new and existing projects. To sort results by family, click Family Sorting
 , located to the right of Include Family .
, located to the right of Include Family .
Also find details in the Administrator Help:
To not overload Jobs tabs, some jobs that are started for a meta engine are only shown for the meta engine level. Sub-jobs on index engine level are no longer shown.
This change concerns:
- Document Export
- Matter Export
- Exception Resolution
- OCR
For better orientation, engine names are now shown on Jobs tabs.
System-based write locks are now protected against manual removal. Write locks created by other administrators can be removed. When trying to save index engines that have been write-locked by another administrator, a system message makes you aware that you first have to unlock the engine.
Document deletion is no longer part of an index engine save, but run as an asynchronous job after the save, making engine saves and engine restarts quicker, and user activity interruptions smaller.
Marking documents as deleted and marking documents as active again is also now run as a job.
See: Document Deletion
- Exchange 2013/Online connector now can use the autodiscovery function for Exchange servers
- If the Exchange Web Services URL setting is empty, autodisovery detects the servers on which mailboxes are located.
- SharePoint 2013/Online connector
- Several improvements were made to this connector:
- After a timeout in the communication with the SharePoint server, retry attempts are now done. The timeout duration and the number of retries are configurable.
- An encoding issue has been fixed, so that SharePoint items with names including the character '+' are now indexed without errors.
- A SharePoint full crawl now starts without errors even if a previous crawl was terminated forcefully and left a corrupted connector database.